 |
Српски |
 |
Srpski |
 |
English |
| PERPETUAL CHECK |
| Front - Tournaments - Search - Rating - Reports - Antichess - Link |
|
|
|
The Truth about Chess Rating14.08.2010 / Andrejic, Vladica (2185)The original article "The Truth about Chess Rating" by Dr Vladica Andrejic you can download in PDF format. The Truth about Chess RatingVladica AndrejićUniversity of Belgrade, Faculty of Mathematics, SerbiaThe Rating Expectation FunctionThe main problem of chess rating system is to determine the f function, which assigns probability to rating difference i.e. to the expected result. It actually means that if the player A whose rating is Ra plays N games against the player B whose rating is Rb, one can expect that A will score N*f(Ra-Rb) points i.e. final ratio of points in the match where A plays against B will be f(Ra-Rb):f(Rb-Ra), where f(Rb-Ra)=1-f(Ra-Rb). Behaviour of chess rating depends on the f function whose features can be observed in the simplest nontrivial case of extensive series of games played between three players A, B and C. In case that we know the final score of the match between A and B as well as the score of the match where B plays against C, will it be possible to predict the score of the match where A plays against C? One of potential hypotheses is that the nature of rating system preserves established ratios. It actually means that if A and B play, and the result is consistent with a:b ratio, and B and C play and the result is consistent with b:c ratio, we expect A and C to play so that the result is consistent with a:c ratio. If we introduce x and y to respectively denote the rating difference between A and B, and B and C, the hypothesis could be expressed as the following functional equation
 that is valid for each real x and y. Simplifying the equation (1) with x=y, results in the following formula
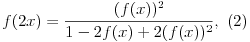 that can be applied more easily. Additionally, it is no trouble to prove that the result of these equations represents the family of functions of the following form
 where C stands for a constant. The very selection of the value of the constant C is irrelevant as it only sets the norm for rating calculation and consequently one rating point correlates with probability f(1)=1/(1+C). In its Handbook FIDE states that formula (3) for the value of
 is a close approximation to real (FIDE) values for f [2], however the FIDE tables are to be exclusively used for calculating [1]. Based on (4) one could say that C was selected so that f(400)=10/11; however 10/11 ~ 0.91, whilst 0.92 is the actual value from the FIDE tables. Entire tables are created in accordance with a different distribution, but the discrepancies between the corresponding values are rather small and they amount up to about 1%. Examination of the HypothesisDoes the ratio preservation law (i.e. – our hypothesis) adequately reflect the real state of things? I questioned it for the first time after I had read the article by Sonas [3] where he proposed linear scale as the alternative. For that reason I carried out several experiments using data from my website Perpetual Check [4] where I have covered almost all significant tournaments (from classical time control over rapid to blitz) organized in Serbia and Montenegro since 2006. In the first experiment I analysed the results of all the games played under classical time control in Serbia and Montenegro where both players had FIDE ratings. My program subdivided the games into 10-point size classes, i.e. rounded the values of the rating difference divided by 10 and statistically processed it. Amusingly enough, it turned out that all the calculated percentages were strictly smaller than the anticipated values (see (3) and (4)), at least for first 50 classes i.e. those where the difference was up to 500 rating points, while the sample was too small for serious interpretation of examples with greater rating difference. Perhaps the explanation of this phenomenon can be found in, I dare say, FIDE's somewhat unreliable rating calculation, especially regarding lower ratings (great majority of players from this experiment have rating under 2400), because the similar experiment gave pretty satisfactory results on super tournaments around the world. Although statistical data calculated in such manner do not reflect the theoretical projection, we can still examine ratios between any of the two corresponding statistical classes. Comparing values on the left and on the right side of equation (2) for the calculated data, we come to the conclusion that they are not that different and thus support the hypothesis. "Beogradski vodovod" Blitz RatingThe second experiment that I carried out was more extreme and based on "Beogradski vodovod" blitz tournaments that were traditionally played almost every Monday and Thursday. Perpetual Check tournament record [4] takes into account 258 such tournaments (mostly 15 rounds Swiss), resulting in a huge database of 49639 blitz games played. FIDE rating is virtually inapplicable in this case, so I had to introduce a special rating for these popular blitz tournaments. The rating system I created was different from FIDE rating in many aspects, and the very article by Sonas [3] was my source of inspiration. It was a linear scale where the difference of a single rating point amounted to a 0.1% increase in the rating expectation function, and the difference of more that 500 rating points matched the probability of a total of 100%. The rating was calculated as (linear) performance over the last 150 played games, where wins that decrease the performance and losses that increase the performance have naturally been excluded. If a player had played less than 150 games, his performance was calculated based on at least 75 games, where draws against virtual opponents rated 2000 were added to these games up to the 75th game. Rating lists were issued monthly and their comparative advantage was the fact that the initial rating was irrelevant, as 10 new tournaments that were to be played would completely eliminate previous results. The main assumption of this experiment is that any logically conceived rating system would be able to differentiate players according to their strength. Therefore basic nature of rating will become visible through relevant statistics. Similarly to the first example, once again I subdivided the games into classes of 10 rating points, and the results of the calculations are shown in the table presented on the following page.
Firstly, let's explain the meaning of each column of the table. The first
column lists the values of Significant discrepancy between the third and fourth column indicates that rating system has been poorly conceived, but small values in the last column show the true nature of chess rating. Beyond a shadow of a doubt this experiment has convinced me that the ratio preservation hypothesis is the natural law that has to be inherent to any chess rating system! As the value of constant C is irrelevant, the easiest thing to do is to use the value from (4) in order to avoid any ambiguities and additional explanations.
In the considerations above we have statistically proved the legitimacy of (1), but it appears unsuitable for simple calculation. For small values of x we can approximate it using the Maclaurin series expansion.  Careful calculation of the first and second derivative of f results in the following formulas  so that for x=0 we have f'(0)=-(1/4)log C and f''(0)=0, which along with (4) yields  That is how we got our approximation 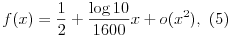 which works well for |x|<100. Hence, for the interval |x|<100 f behaves linearly, and since 1600/log10 ~ 695, we can conclude that  The previous calculation proves the commonly known fact among chess players that each percent over 50% amounts to 7 (or more precisely – 6.95) rating points. Influence of the last gameIn the following considerations we would like to examine the influence of the last game. Therefore, we will assume player's official rating to be R0, but as he has advanced (or regressed) in the meantime his new rating is R1. If he plays a single game, according to the FIDE Handbook [1] it will produce the difference between the actual and expected result multiplied by K, where K represents the player's development coefficient. Thus we reach the expected rating increase of K(f(R1-R0)-1/2). Furthermore, let's assume that our player has played N-1 games in accordance with his (former) playing strength as measured by his "old" rating, and than played a game with new (different) strength. Now, player's performance is ((N-1)R0+R1)/N and therefore we can say that he earned (R1-R0)/N rating points. Comparing the two results we get 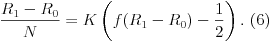 For easier calculation, we will use the approximation (5) for  and finally  Furthermore, we can even perform the calculation without the approximation. Since f'''(0)=(1/8)(log C)^3<0, it can easily be shown that f(x) < 1/2 + (log10)x/1600, for x>0, and also symmetrically f(x) > 1/2 + (log10)x/1600, for x<0. If compared again using (6), we can conclude that  is certainly valid. Thus, approximation (7) actually provides the minimal value of KN. A previously unrated player's ratingFIDE currently uses three development coefficients for rating calculations: "K=25 for a player new to the rating list until he has completed events with at least 30 games; K=15 as long as a player's rating remains under 2400; K=10 once a player's published rating has reached 2400 and remains at that level subsequently, even if the rating drops below 2400" [1]. Based on the result (7) one can conclude that the influence of the last played game is the same if it were one among the total of 695/K games played. Now, let's pay attention to the previously unrated player. According to FIDE Handbook, when one plays at least 9 games against rated players, for results up to 50% his rating will be calculated as a performance rating of some sort, and if he scores more than 50%, he will get the average rating of all opponents plus 12.5 rating points for each half point scored over 50% [1]. Now let's observe the appearance of a previously unrated player after a 9-round tournament (K=25). As long as he has that coefficient (first 30 games), his last game will be valued as the one of 695/K ~ 28 according to (7), though the actual number of games played is much smaller than that; (8) is even more extreme, where we can notice that first 9 games are valued as if they were played under the coefficient K > 695/9 ~ 77, only to be followed by a sudden drop to 25. Even greater injustice has been imposed on players who initially made more than 50% and gained only 12.5 rating points for each half point over that, because they were earning bonuses according to coefficient 25 despite the fact that those games required three times larger coefficient. Consequently, we may conclude that the FIDE's solution for the previously unrated players is not the best one, which may have far-reaching consequences. If a player gets an inadequately calculated initial rating, it will take him some time and effort (and certainly a lot of games) to reach the level proportional to his strength, while in the meantime he (positively or negatively) influences the rating of his opponents. What I would like to suggest is to simultaneously provide player with a sliding coefficient K=695/N as soon as he gets his initial rating, where N represents the ordinal number of a game (in a chronological order) that he has played against rated players. In comparison with (7) it is a good approximation, while according to (8) it is a minimum that should be set. The sliding coefficient should be valid until it falls under the value of K0 intended for players with stable rating, i.e. until the number of played games is under 695/K0. Naturally, a player's rating should be stabilized prior to claiming any international title standards/considerations. There is a possibility of a more radical solution: one could assign a so-called initial rating to all players at the beginning of the event, to be followed by the above mentioned procedure with a possible decrease of coefficient K for extremely small values of N (primarily N=1 and N=2). In that case (small number of games), the player's rating is utterly unreliable, and his opponent's coefficient should also be modified (especially if he has a stable K0). I believe that if the opponents have coefficients K and K1 < K, the second one (K1) should be adjusted by multiplication with K1/K. The best KRegarding the best K0 value, experiments that I have carried out showed that if we have a well-conceived rating system the coefficient K should be as small as possible. In my opinion, the main problem is the badly conceived introduction of a previously unrated player, and I think that values between 10 and 16 are quite fair. However, I can hardly endorse the introduction of greater values of development coefficients for players with stable rating as it would completely devastate the very essence of rating system. Additionally, I believe that there should not be any discrimination as to whether a player has ever exceeded the 2400-point plateau in his career, and thus acquired a different coefficient. Rating PerformancePlayer's performance has been an extremely important issue during past years because it is what brings grandmaster and international master norms. Nevertheless, the way this performance is calculated is quite controversial, and it is Ra+f^{-1}(p) where Ra is the average rating of the opponents, while p stands for percentage that the player has obtained during the tournament. It is a common occurrence in many tournaments that certain opponents have ratings so small that beating them actually decreases one's performance; for that reason and for the sake of norm performance rating of the worst rated player is boosted so that the game can eventually be improved. I would suggest defining performance as the rating that would be preserved during the process of rating of the tournament in question (game by game). It can easily be calculated iteratively, and the good thing is that iterative calculation does not depend on the development coefficient that is also included in the FIDE calculation. For these calculations I would not use rounded values from the table, but the real values of f without any rating limits like those of 400 rating points. Winning the game would certainly not harm the winner, and other things would also be improved. For example, let's assume that a player gains 1.5 points in two games with the opponents' average rating of 2400. FIDE's calculation of such performance would be 2591 (or 2593 according to the tables). That would also be the value of my calculation, but only if both players have 2400. However, as we have already shown, rating is not linear, so if our players have 2300 and 2500 the performance is 2605, and if the players have 2200 and 2600 – the performance is 2648! Such an iterative calculation will always converge to the value of our performance, except in the case of all wins (or losses) when naturally it can not be calculated. References
|
|
 (rating class),
that is, of situations
where the rating difference is about 10
(rating class),
that is, of situations
where the rating difference is about 10